


Today we will look into introduction into Data Engineering understand what a data engineering entails about, what tools a data engineer uses and what a data engineer should learn. This article will help developers who want to begin a career in data engineering.
What is Data Engineering?
Data Engineering is a series of process that involves designing, building for collecting, storing, processing and analyzing large amount of data at scale. It is a field that involves developing and maintaining large scale data processing systems to prepare data to be available and usable for analysis and make business-driven decisions.
The image below tells us about the process that involved in data engineering.
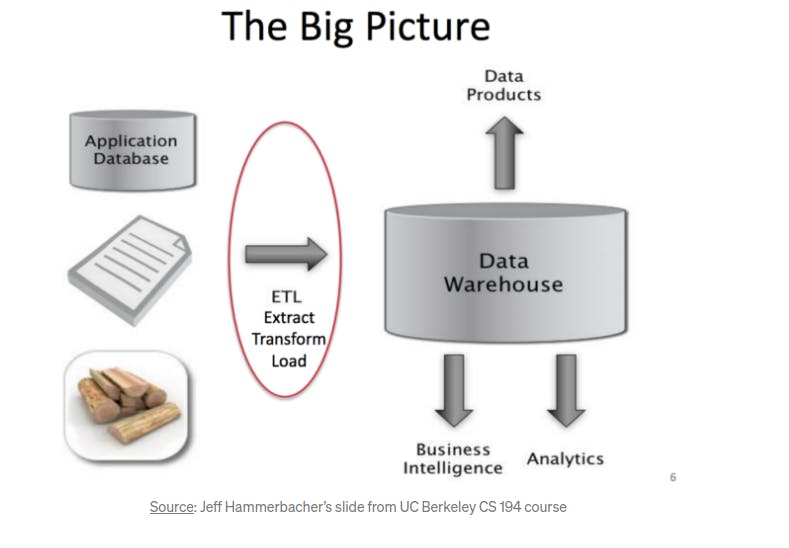
Who is a data engineer and what does a data engineer do?
A data engineer refers to a person who is responsible for building data pipelines from different sources and prepares data for analytical and operational uses. Data engineers are responsible for laying the foundations for the acquisition, storage, transformation, and management of data in an organization. They do design, build, and maintain data warehouses. A data warehouse is a place where raw data is transformed and stored in query-able forms.
Most importantly, the Data Engineering ecosystem consists of the following:
Data — different data types, formats, and sources of data.
Data stores and repositories — Relational and non-relational databases, data warehouses, data marts, data lakes, and big data stores that store and process the data.
Data Pipelines — Collect/Gather data from multiple sources, clean, process and transform it into data which can used for analysis.
Analytics and Data driven Decision Making — Make the well processed data available for further business analytics, visualization and data driven decision making.
ETL Data Pipeline
A data pipeline is essentially a collection of tools and methods for transferring data from one system to another for storage and processing. It collects data from several sources and stores it in a database.
ETL(Extract, Transform and Load) involves extracting, transformation and loading tasks across different environments.
These three conceptual steps are how most data pipelines are designed and structured. They serve as a blueprint for how raw data is transformed to analysis-ready data.
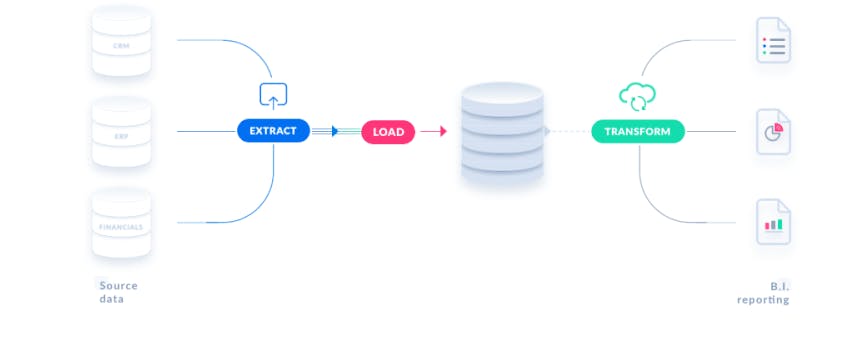
Lets us explain these steps to understand
Extract: this is the step where sensors wait for upstream data sources to land then we transport the data from their source locations to further transformations.
Transform: where we apply business logic and perform actions such as filtering, grouping, and aggregation to translate raw data into analysis-ready datasets. This step requires a great deal of business understanding and domain knowledge.
Load: Finally, we load the processed data and transport them to a final destination. Often, this dataset can be either consumed directly by end-users.
Data Warehousing
A data warehouse is a database that stores all of your organization historical data and allows you to conduct analytical queries against it. It is a database that is optimized for reading, aggregating, and querying massive amounts of data from a technical point of view. Modern Data Warehouse can integrate structured and unstructured data.
Four essential components are combined to create a data warehouse:
- Data warehouse storage.
- Metadata.
- Access tools.
- Management tools.
Which skills are required to become data engineers?
Data engineers require a significant set of technical skills to address their tasks such as:
Database management: Data engineers spend a considerable part of their daily work operating databases, either to collect, store or transfer data. One should have the basic understanding of relational databases such as MySQL, PostgreSQL and non-relational databases such as MongoDB, DynamoDB and work efficiently with this databases.
Programming languages: Data engineers use programming languages for a wide range of tasks. There are many programming languages that can be used in data engineering, Python is certainly one of the best options. Python perfect for executing ETL jobs and writing data pipelines. Another reason to use Python is its great integration with tools and frameworks that are critical in data engineering, such as Apache Airflow and Apache Spark.
Cloud technology: Being a data engineer entails, to a great extent, connecting your company’s business systems to cloud-based systems.Therefore, a good data engineer should know and have experience in the use of cloud services, their advantages, disadvantages, and their application in Big Data projects. We have cloud platforms such as Amazon Web Services(AWS), Microsoft Azure, Google Cloud Platform which are widely used.
Distributed computing frameworks: A distributed system is a computing environment in which various components are spread across multiple computers on a network. Distributed systems split up the work across the cluster, coordinating the efforts to complete the job more efficiently. Distributed computing frameworks, such as Apache Hadoop and Apache Spark, are designed for the processing of massive amounts of data, and they provide the foundations for some of the most impressive Big Data applications.
Shell: Most of the jobs and routines of the Cloud and other Big Data tools and frameworks are executed using shell commands and scripts. Data engineers should be comfortable with the terminal to edit files, run commands, and navigate the system.
ETL frameworks: Data engineers do create data pipelines with ETL technologies and orchestration frameworks. In this section, we could list many technologies, but the data engineer should know or be comfortable with some of the best known–such as Apache Airflow. Airflow is an orchestration framework. It’s an open-source tool for planning, generating, and tracking data pipelines. We also have other ETL frameworks, I would advise you to research more on this in order to understand about them.
Why then should we consider data engineering?
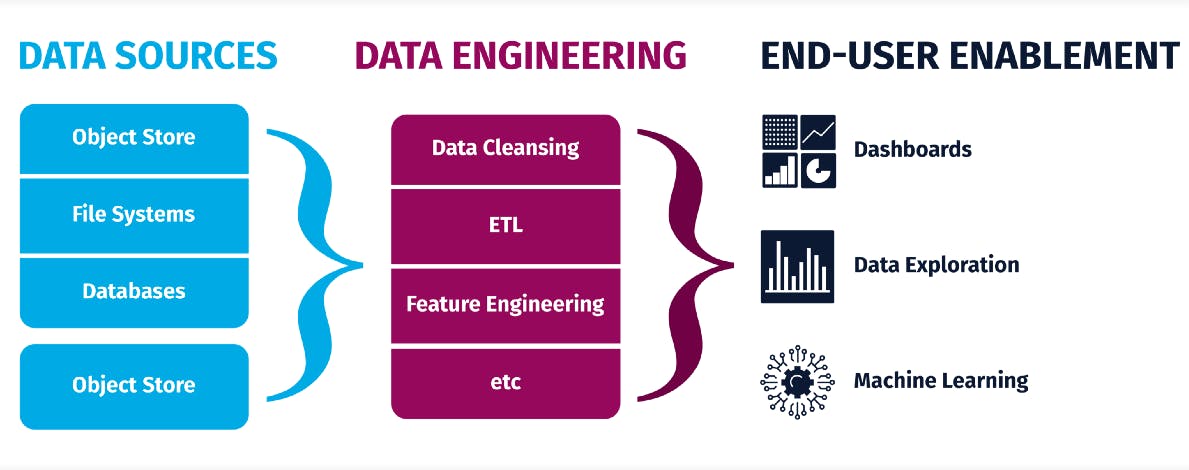
Data engineering helps firms to collect, generate, store, analyze, and manage data in real-time or in batches. We can achieve this while constructing data infrastructure, all thanks to a new set of tools and technologies. It focuses on scaling data systems and dealing with various levels of complexity in terms of scalability, optimization and availability.
How are data engineers different from data scientists and machine learning scientists?
Data engineer is responsible for making quality data available from various resources, maintain databases, build data pipelines, query data, data pre-processing, feature Engineering, works with tools such as Apache Hadoop and spark, Develop data workflows using Airflow On the other hand, ML Engineers and Data Scientists are responsible for building Machine Learning algorithms, building data and Machine Learning models and deploy them, have statistical and mathematical knowledge and measure, optimize and improve results.
That's it for our introduction to data engineering, I would advise you as a reader to read this article for understanding the basics and prerequisites in data engineering.
I will continue writing about Data Engineering till this year ends, so join me as we read about data engineering together.
Remember give your feedback about this article.
Happy Learning!!